RAG向量存储在N8N中的应用
RAG全名是Retrieval-Augmented Generation,翻译成中文叫检索增强生成,名字听上去很绕口。
我尝试用费曼学习法结合我自己理解的方式解释一遍,解释的不对还请业内人士斧正。
在很多的场景下,比如企业自部署的AI客服机器人,在回答用户的提问的时候,一定是要结合内部的知识库再加上AI自己的思考回答,而不是乱回答,在这种情境下,AI Agent需要先提取向量存储数据。
一个完整的大语言模型向量检索过程如下

向量检索
当用户发出一个聊天触发N8N,AI Agent节点会调用之前整理的向量存储数据,在这个调用过程中会进行检索,检索出最能符合用户问题的数据仓库。
比如用户询问,GEO和SEO有什么区别,AI Agent会立马调用检索查找之前的标签数据库,找到跟”GEO”,”SEO”,”区别”这三个标签相关的向量vector,为下一步AI Agent思考推理做好素材准备。
在上图中,向量检索是在Tools中执行的,A Collection和B Collection分别代表两组数据。
向量存储
向量存储就是先上传一些内部的数据或者文件,比如JSON,Markdown,PDF等格式的数据,存储到向量数据库中,等待下一步被分拣打标签。
被分拣后的数据分门别类存储到不同标签的仓库中
比如,苹果,香蕉,橘子被放到门口贴有”水果“标签的仓库中,”猴子,老虎,大象“被存储到贴有”动物“标签的仓库中。
有了这些存储,AI Agent进行向量检索的时候才能找到,比如用户提问:苹果和大象有什么区别吗,AI Agent通过向量检索在之前的动物和水果仓库中检索相关的数据。
有了以上的基本认识,我们看下N8N是如何实现RAG的。
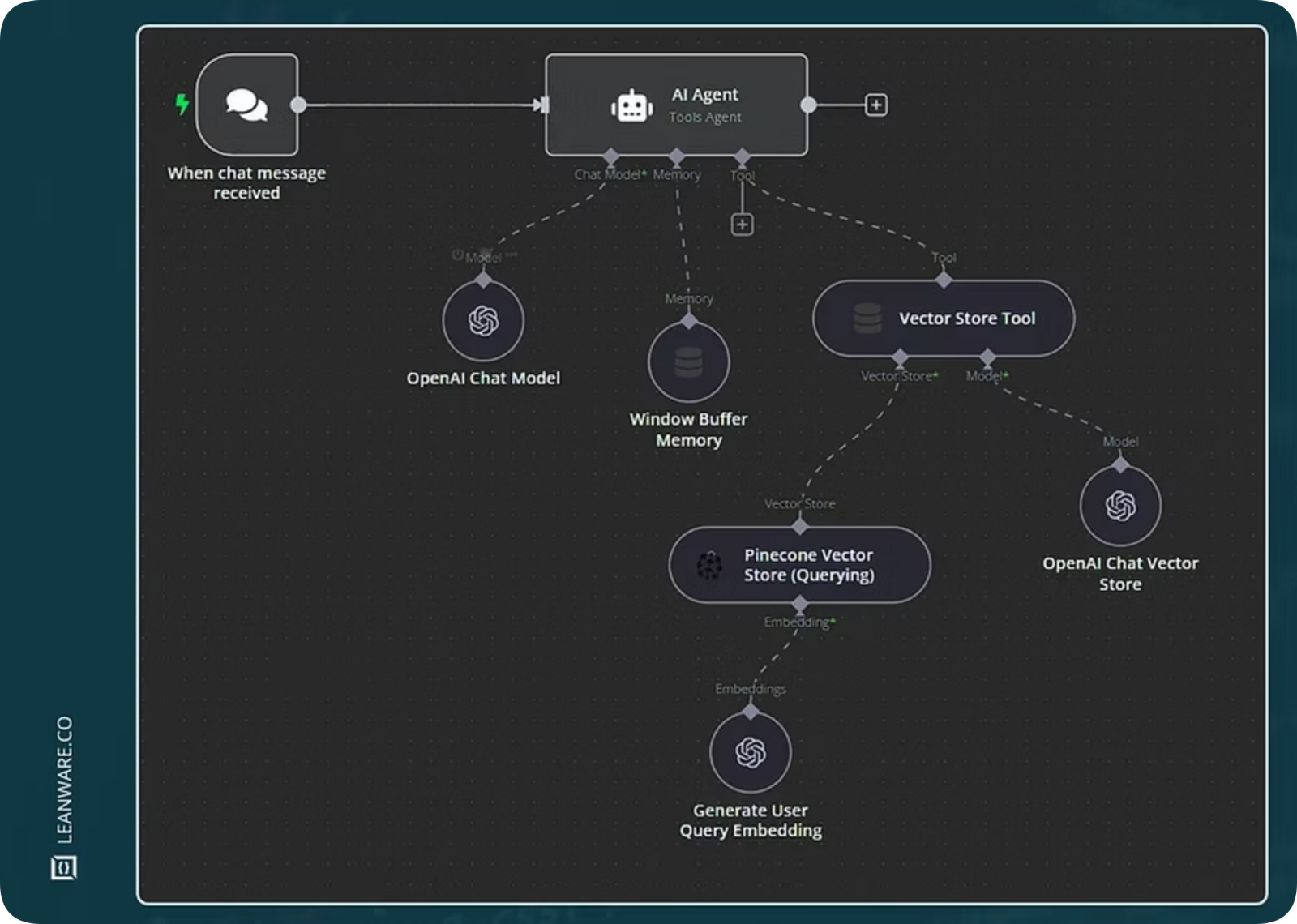
上面这个图片展示的是一个N8N搭建的AI聊天机器人工作流
其中在AI Agent节点中,我们看到通过添加一个tool-vector store tool来实现RAG。
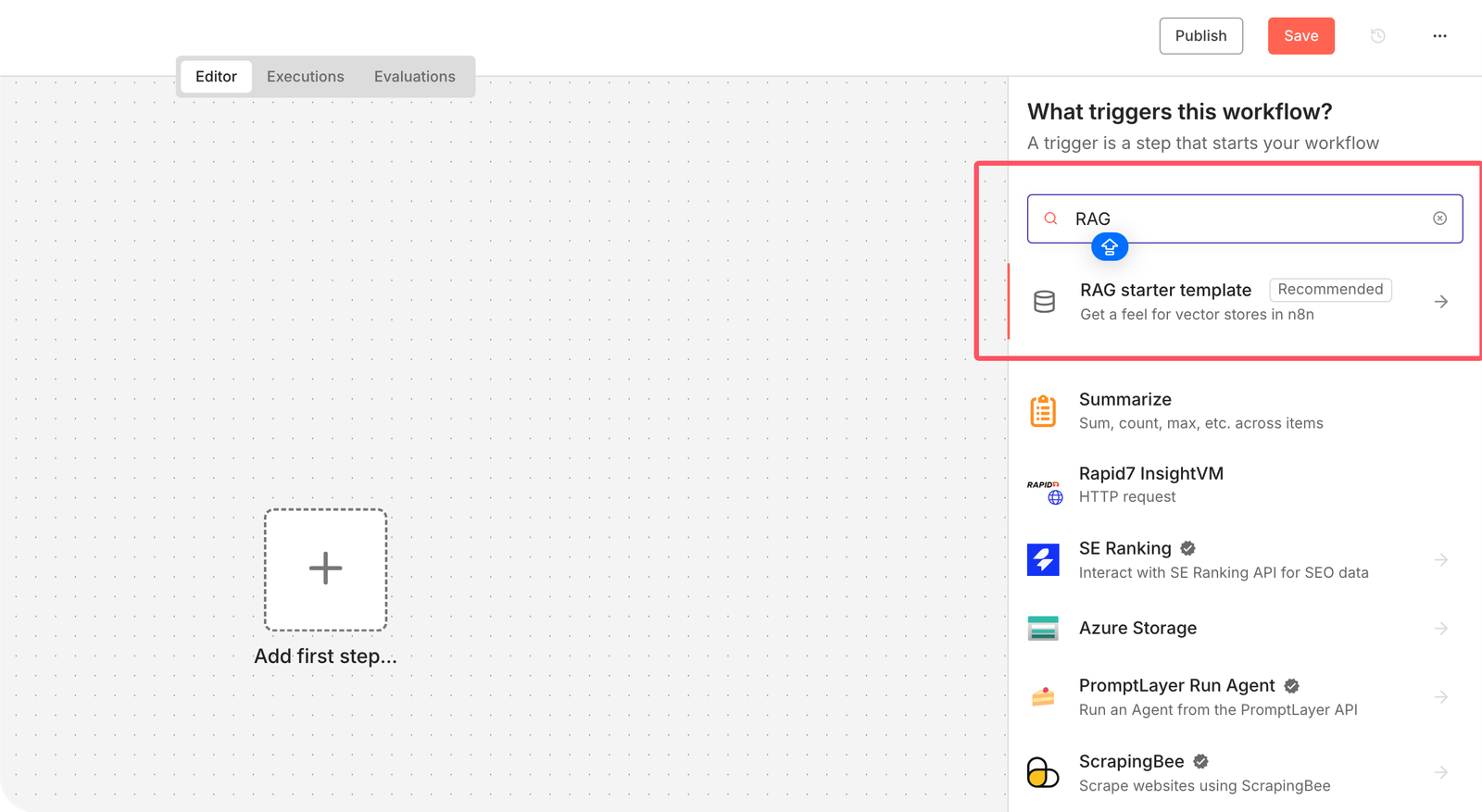
如果你看不懂上面这个图片没关系,N8N官方有1个专门的AI Chatbot Workflow模板,你可以通过这个模板来深刻的体验RAG在N8N中的实现过程。
在N8N后台create a new workflow,不知道后台怎么进的,看下《N8N入门教程》
在画布右上角点击+标志,就是新建节点,然后搜索框输入RAG,出现了一个Recommended RAG Starter template,直接点击。
在这个RAG Demo中 有左右两部分,左边展示的是数据存储流程,右边是一个AI Agent调用向量存储进行交互的流程
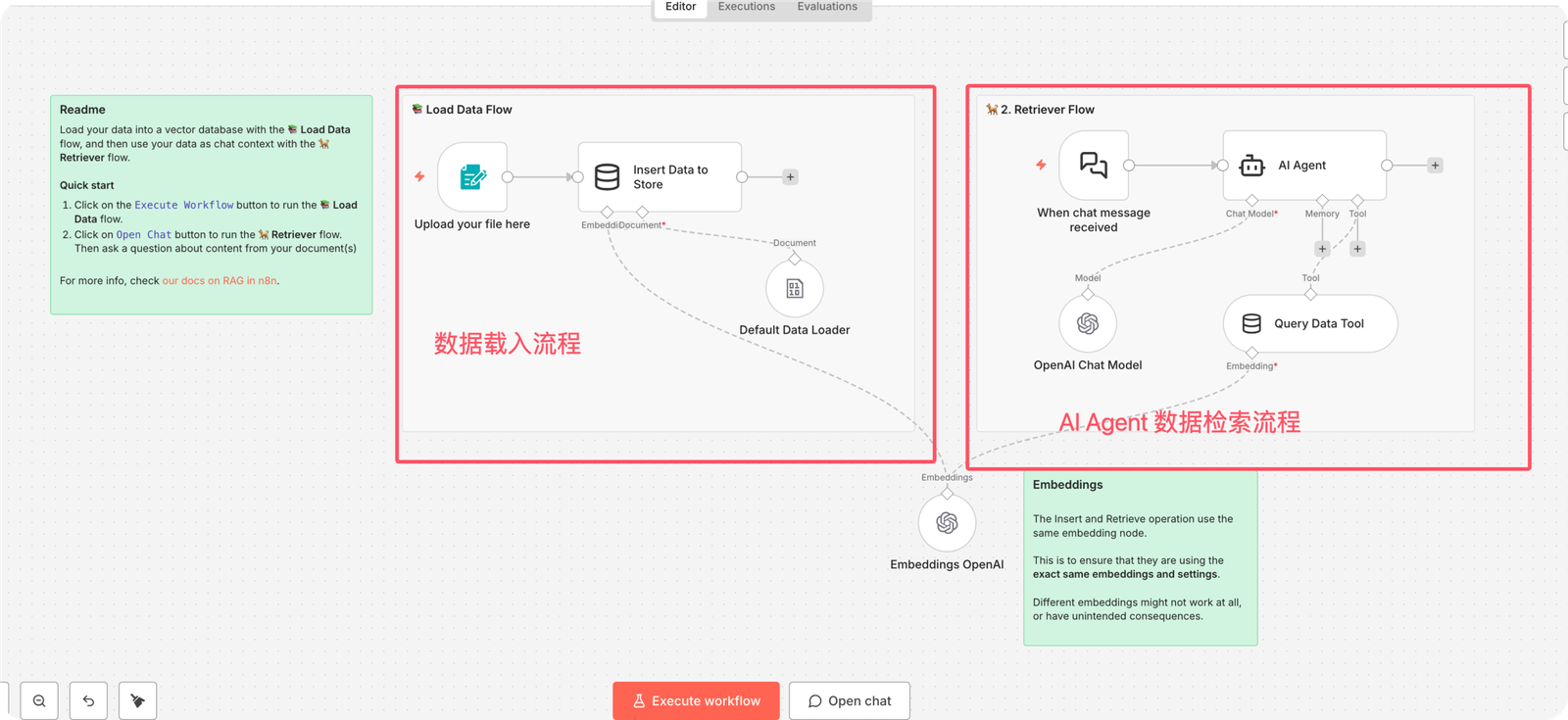
左右两边的桥梁是OpenAI的嵌入embedding节点,左侧数据的分拣是通过Embedding节点这个桥梁进行的。
以上就是RAG在N8N工作流的实现过程,希望你们能看得懂,看不懂没关系,直接在这个RAG Demo里面上手操作一遍就全都明白了。